Current diffusion models need an impractical number of tokens for high-resolution generation, while
existing high-compression tokenizers require retraining the diffusion backbone from scratch.
DA-VAE offers a plug-in alternative: it upgrades a pretrained VAE into a structured base+detail
latent with higher compression, then fine-tunes the diffusion model on top — preserving what
was already learned. On SD3.5-Medium, DA-VAE generates 1024×1024 images with only
32×32 tokens (4× fewer than the default 64×64), achieving competitive quality at
~4× throughput.
Generation Results
All images below are generated by SD3.5-Medium + DA-VAE using only 32×32 latent tokens.
The rest of this page is organized as follows:
- Motivation: why current tokenizers are a bottleneck for high-res diffusion.
- Method: structured base+detail latent, alignment loss, and warm-start fine-tuning.
- Results: 1K generation at 32×32 tokens on SD3.5-M with competitive quality.
- Ablations: why alignment and warm-start each matter.
Click to jump to each section.
Why Do We Need a Better Tokenizer?
Scaling diffusion models to higher resolutions exposes fundamental limitations of current VAE tokenizers.
With a standard 8× downsample VAE, a 1024×1024 image requires a 128×128 → 64×64
(with patch size 2) token grid; a 4K image would need 65,536 tokens — making
attention (which scales quadratically) prohibitively expensive.
Problems with current tokenizers
- Too many tokens for high-res. At 4K resolution, standard VAEs produce 65,536 tokens.
Attention cost becomes the dominant bottleneck, not model capacity.
- High channels, unstructured latents. To achieve high spatial compression without
sacrificing reconstruction, current tokenizers compensate by increasing the number of latent channels.
But many of these channels end up encoding unstructured high-frequency residuals that are
difficult for diffusion to model — lower-dimensional latent spaces are empirically much
easier to learn.
- Retraining from scratch. Existing high-compression approaches (e.g., DC-AE) require
first training a new tokenizer, then retraining the diffusion backbone from zero on the new latent
space. This wastes the pretrained prior entirely.
- Imperfect reconstruction. When channel capacity is limited,
fine details (small text, textures) are lost at the tokenizer stage — no amount of
diffusion training can recover them.
Two key questions
These problems lead us to two questions that motivate DA-VAE:
- Does a 1K image really need 4× the tokens of a 512 image?
Much of the additional content at higher resolution is local detail, not new global structure.
If we can encode that detail into extra channels instead of extra spatial tokens, we can keep
the token grid compact.
- Can we increase VAE compression without retraining the diffusion model from scratch?
A well-trained diffusion backbone already captures rich priors. Instead of discarding it,
DA-VAE upgrades the tokenizer in a plug-in fashion and fine-tunes on top.
Method
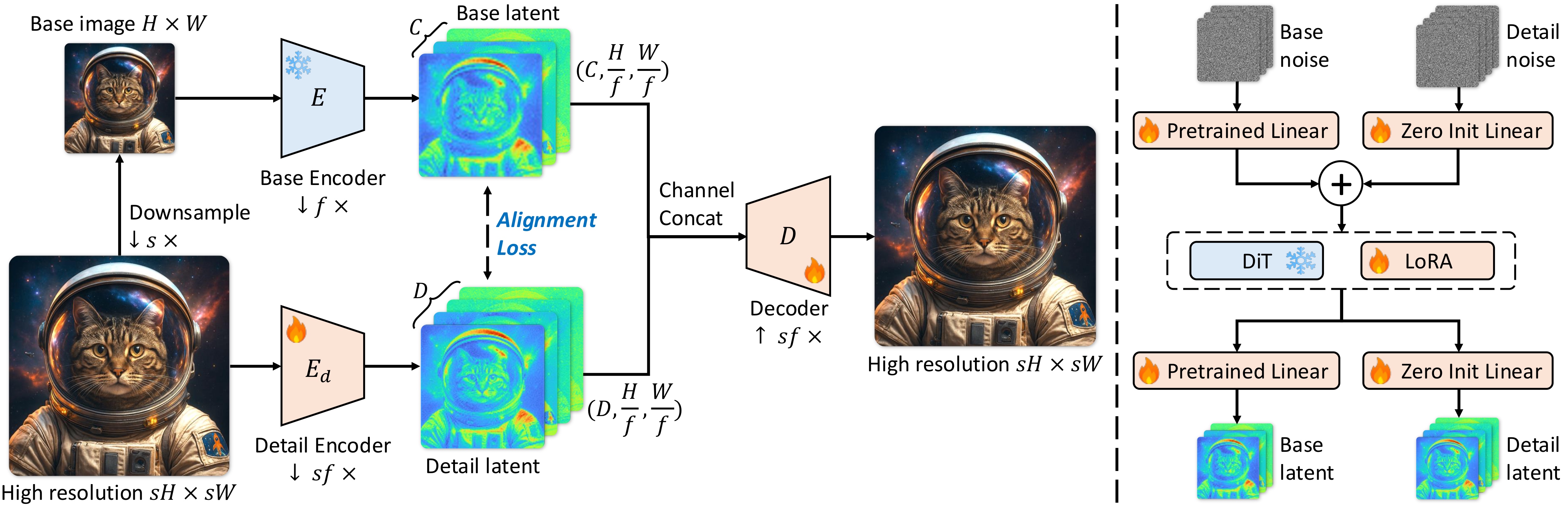
DA-VAE consists of (i) a structured latent space that reuses the pretrained latent as the first channels,
(ii) a simple alignment loss that regularizes the new detail channels, and (iii) a warm-start recipe that
adapts a pretrained DiT with minimal disruption.
The following overview figure (Fig. Method) summarizes the full method; the rest of this section unpacks
it into three components.
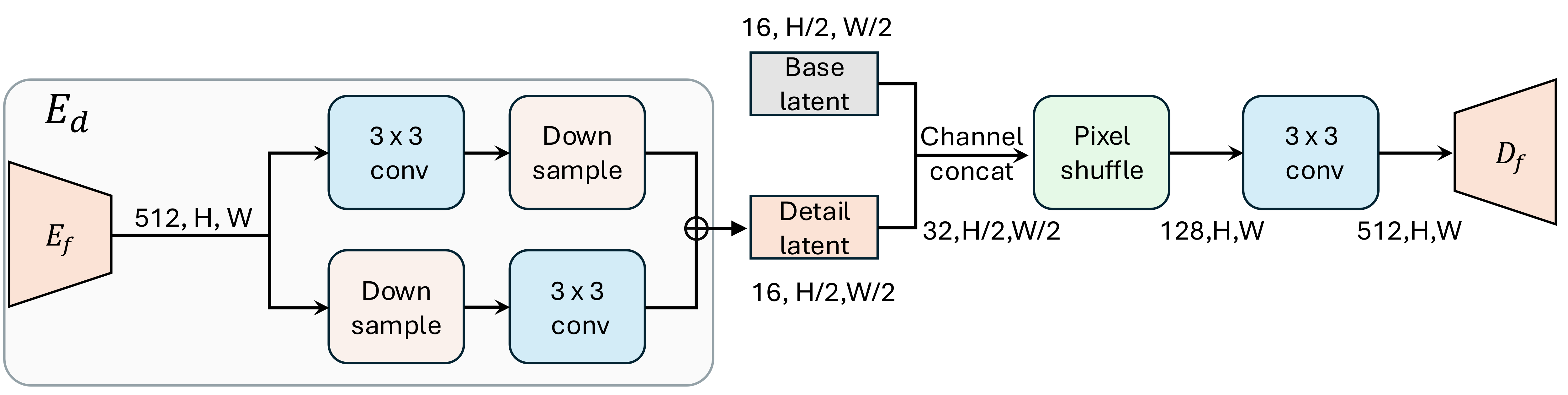
1) Structured base + detail latent
Let a pretrained VAE encoder produce a base latent z for a base-resolution image, with
C channels. DA-VAE encodes the corresponding high-resolution image with the same spatial
token grid, but with C + D channels by concatenating (a) the unchanged pretrained latent
channels and (b) an additional D-channel detail latent z_d. A single
decoder reconstructs the high-resolution image from [z, z_d].
In terms of tokenizer efficiency, this design supports increasing spatial compression (downsampling) while
compensating capacity in the channel dimension. In experiments, the paper sets the high-resolution scale
factor to s = 2 (e.g., 512 to 1024), keeping the token grid fixed while expanding channels.
2) Detail alignment (make z_d diffusion-friendly)
Without additional structure, extra channels tend to absorb noisy residuals and are hard for diffusion to
model. DA-VAE introduces a latent alignment loss that encourages z_d to mirror the
structure of the pretrained latent z, using a parameter-free grouped channel reduction
to compare the two (see Alignment analysis in Ablations).
Concretely, the paper projects z_d back to C channels via grouped
averaging (with group ratio r = D / C) and minimizes an L2 distance to the base latent.
Training-wise, the paper keeps the original encoder for z fixed and optimizes the detail
encoder and decoder with standard reconstruction losses plus the alignment loss. This is a deliberate
choice: the base channels remain a stable reference for both reconstruction and diffusion fine-tuning.
3) Warm-start diffusion fine-tuning
To adapt a pretrained DiT to the expanded latent, DA-VAE adds an extra patch embedder and output head for
the new detail channels. These added modules are zero-initialized, so the model is
functionally identical to the pretrained DiT at the start of fine-tuning. A gradual loss
scheduling further down-weights the detail-branch loss early on, then ramps it up to encourage the
model to learn the new channels stably.
For large backbones such as SD3.5, the paper applies LoRA to attention and FFN layers while still training
the (added) patch embedder and output heads, matching the warm-start objective: preserve what is already
learned, and focus adaptation capacity on the interface to the new latent channels.
Results
This section summarizes the main empirical takeaways and points to the exact tables/figures used as
evidence. For qualitative evidence, jump to Qualitative Results.
Text-to-image: SD3.5-M at 1024x1024 with fewer tokens
Takeaway: DA-VAE enables 1K generation with a 32x32 token grid while keeping SD3.5-M quality competitive.
Evidence: On MJHQ-30K at 1024x1024, DA-VAE achieves FID 10.91 / CLIP 31.91 / GenEval 0.64 at 1.03 img/s using 32x32 tokens, while SD3.5-medium uses 64x64 tokens at 0.25 img/s (see SD3.5 Results).
Additional evidence: Under the same 32x32 token grid and throughput, DA-VAE improves over the SD3.5 upsample baseline (FID 10.91 vs 12.04, CLIP 31.91 vs 30.17; SD3.5 Results).
Interpretation: By allocating capacity into aligned detail channels (instead of more spatial tokens), DA-VAE improves throughput (about 4x vs SD3.5-medium in this table) without requiring a new diffusion model from scratch.
- What "32x32 tokens" means: the diffusion model operates on a 32-by-32 latent grid rather than 64-by-64 at 1K, reducing attention cost substantially.
- Where quality is measured: FID/CLIP/GenEval are reported under the paper's MJHQ-30K protocol at 1024x1024.
- Where to see visuals: the 1K comparison and the 2K comparison.
SD3.5 Results (MJHQ-30K, 1024x1024)
| Method |
Autoencoder |
Tokens |
Params (B) |
Throughput (img/s) |
FID |
CLIP Score |
GenEval |
| PixArt-Sigma |
NA |
64x64 |
0.6 |
0.40 |
6.15 |
28.26 |
0.54 |
| Hunyuan-DiT |
NA |
64x64 |
1.5 |
0.05 |
6.54 |
28.19 |
0.63 |
| SANA-1.5 |
DC-AE (f32c32p1) |
32x32 |
4.8 |
0.26 |
5.99 |
29.23 |
0.80 |
| FLUX-dev |
FLUX-VAE (f8c16p2) |
64x64 |
12 |
0.04 |
10.15 |
27.47 |
0.67 |
| SD3-medium |
SD3-VAE (f8c16p2) |
64x64 |
2.0 |
0.36 |
11.92 |
27.83 |
0.62 |
| SD3.5-medium |
SD3-VAE (f8c16p2) |
64x64 |
2.5 |
0.25 |
10.31 |
29.74 |
0.63 |
| SD3.5-medium (upsample) |
SD3-VAE (f8c16p2) |
32x32 |
2.5 |
1.03 |
12.04 |
30.17 |
0.63 |
| Ours (SD3.5-M + DA-VAE) |
DA-VAE (f16c32p2) |
32x32 |
2.5 |
1.03 |
10.91 |
31.91 |
0.64 |
Notes: Throughput is measured on a single A100 (BF16, batch size 10) under the paper's protocol. Several
baseline rows are copied under the same evaluation protocol as stated in the paper table caption.
Class-conditional generation: ImageNet 512x512
Takeaway: DA-VAE adapts a pretrained generator to a more compressed latent setting and achieves strong ImageNet performance under fine-tuning.
Evidence: With DA-VAE (f32c128p1) at 16x16 tokens, fine-tuning reaches FID-50k 4.84 and IS 314.3 with CFG at 80 epochs (see ImageNet 512x512).
Additional evidence: The table also shows that DA-VAE reaches strong performance even at 25 epochs (FID-50k 6.04, IS 277.6), highlighting the efficiency of the warm-start recipe under limited budgets (see ImageNet 512x512).
Interpretation: The structured latent and warm-start recipe enable a favorable fine-tuning regime compared to training from scratch for new tokenizers.
ImageNet 512x512: Efficiency and Performance
| Method |
Training Regime |
Autoencoder |
rFID |
Tokens |
Epochs |
FID-50k (w/o CFG) |
FID-50k (w/ CFG) |
Inception Score |
| DiT-XL |
Scratch |
SD-VAE (f8c4p2) |
0.48 |
32x32 |
2400 |
12.04 |
3.04 |
255.3 |
| REPA |
Scratch |
SD-VAE (f8c4p2) |
0.48 |
32x32 |
200 |
NA |
2.08 |
274.6 |
| DiT-XL |
Scratch |
DC-AE (f32c32p1) |
0.66 |
16x16 |
2400 |
9.56 |
2.84 |
117.5 |
| DC-Gen-DiT-XL |
Fine-tune |
DC-AE (f32c32p1) |
0.66 |
16x16 |
80 |
8.21 |
2.22 |
122.5 |
| LightningDiT-XL* |
Scratch |
VA-VAE (f16c32p2) |
0.50 |
16x16 |
80 |
21.79 |
3.98 |
229.7 |
| LightningDiT-XL |
Fine-tune |
VA-VAE (f16c32p2) |
0.50 |
16x16 |
80 |
11.31 |
3.12 |
254.5 |
| Ours (DA-VAE) |
Fine-tune |
DA-VAE (f32c128p1) |
0.47 |
16x16 |
25 |
6.04 |
2.07 |
277.6 |
| Ours (DA-VAE) |
Fine-tune |
DA-VAE (f32c128p1) |
0.47 |
16x16 |
80 |
4.84 |
1.68 |
314.3 |
Notes: Some reference numbers are copied directly from prior work as indicated in the paper (see table
caption in the LaTeX source).
Autoencoder trade-off: reconstruction vs generation
Takeaway: DA-VAE improves generation quality while keeping reconstruction metrics competitive.
Evidence: Among compared autoencoders, DA-VAE reports the best FID-10k (31.51) while maintaining rFID 0.47 / PSNR 28.53 / LPIPS 0.12 / SSIM 0.78 on ImageNet val reconstructions (see Autoencoder Trade-off).
Interpretation: This supports the paper's claim that a structured latent with alignment can be more diffusion-friendly than naively increasing channel width.
Autoencoder Trade-off (ImageNet val reconstruction + generation)
| Autoencoder |
rFID (down) |
PSNR (up) |
LPIPS (down) |
SSIM (up) |
FID-10k (down) |
| SD-VAE (f8c4p4) |
0.48 |
29.22 |
0.13 |
0.79 |
58.17 |
| DC-AE (f32c32p1) |
0.66 |
27.78 |
0.16 |
0.74 |
35.97 |
| VA-VAE (f16c32p2) |
0.50 |
28.43 |
0.13 |
0.78 |
44.65 |
| DA-VAE (f32c128p1) |
0.47 |
28.53 |
0.12 |
0.78 |
31.51 |
Qualitative Results
These figures complement the tables above by showing where detail channels help: richer local textures,
fewer structural failures, and better prompt-faithful composition. For the SD3.5 comparisons, the paper's
baseline is produced by generating at 512x512 then upsampling to 1K.
- Look for: fine-grained textures (foliage, fur, text), and whether complex layouts remain coherent.
- Link: quantitative summary in SD3.5 Results.
- Look for: large-object distortion and scene-layout collapse in the naive 2K baseline.
- Link: teaser highlights a reported 6.04x speedup at 2K (Fig. Teaser).
Ablations
This section explains why the method components matter, using targeted ablations and diagnostics.
Each claim below is tied to the corresponding table/figure.
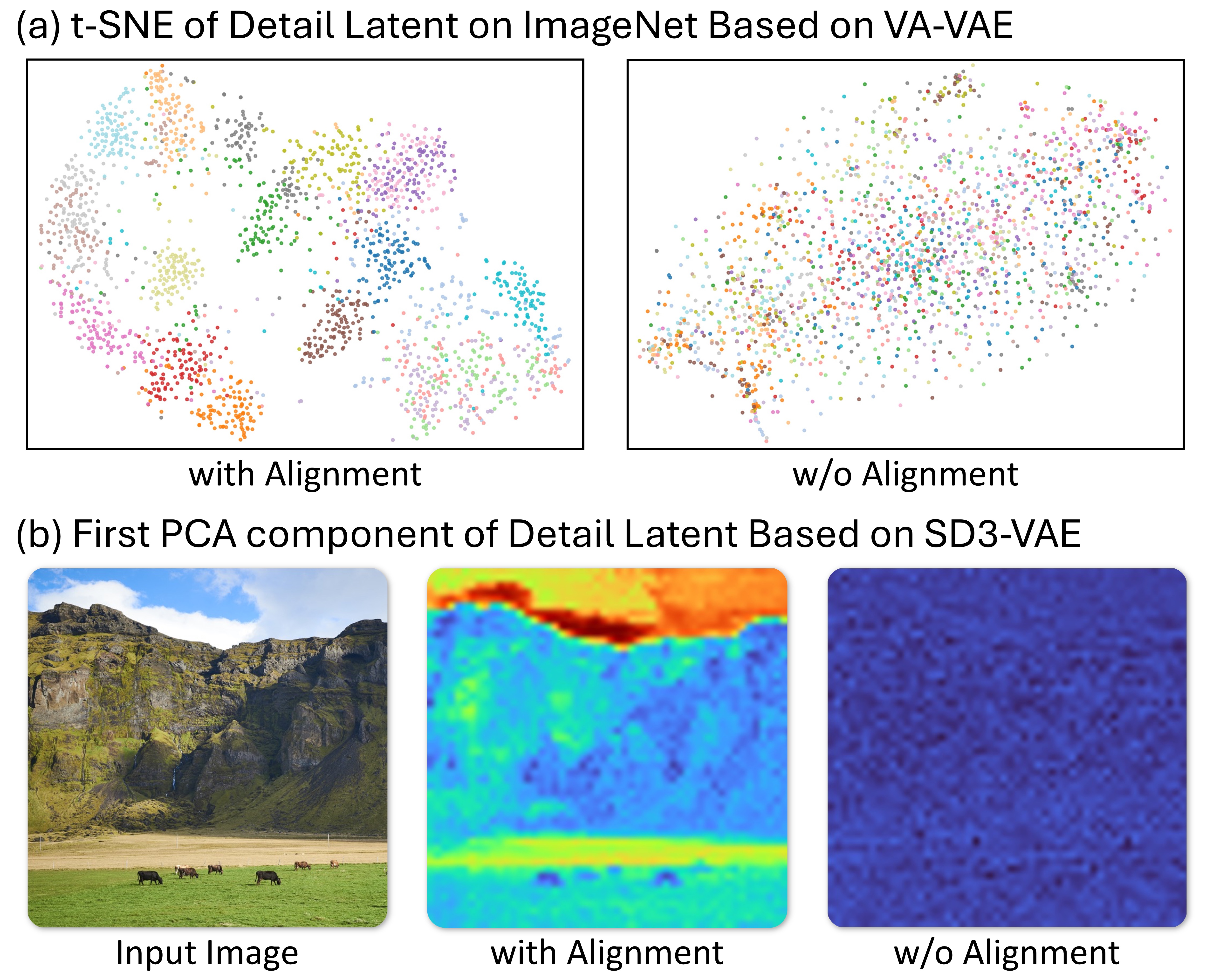
Alignment is necessary for a structured detail latent
Takeaway: Without alignment, the detail channels become unstructured and generation quality drops.
Evidence: In component ablations, removing alignment increases FID-10k from 9.27 to 16.37 (see Component Ablations), and the alignment visualization shows more organized features under alignment (see Fig. Alignment).
Interpretation: Alignment turns the added width into usable structure rather than noisy residual capacity.
Alignment Weight Ablation
| Alignment Weight |
rFID |
PSNR |
LPIPS |
SSIM |
FID-10k |
| 0.0 |
0.59 |
29.23 |
0.11 |
0.80 |
16.37 |
| 0.1 |
0.55 |
28.70 |
0.12 |
0.79 |
9.58 |
| 0.5 |
0.47 |
28.53 |
0.12 |
0.78 |
9.27 |
| 1.0 |
0.63 |
27.90 |
0.14 |
0.76 |
9.23 |
Reading guide: increasing alignment weight tends to improve generation FID-10k while slightly degrading
reconstruction metrics; the paper uses a moderate weight (0.5) as a trade-off in other experiments.
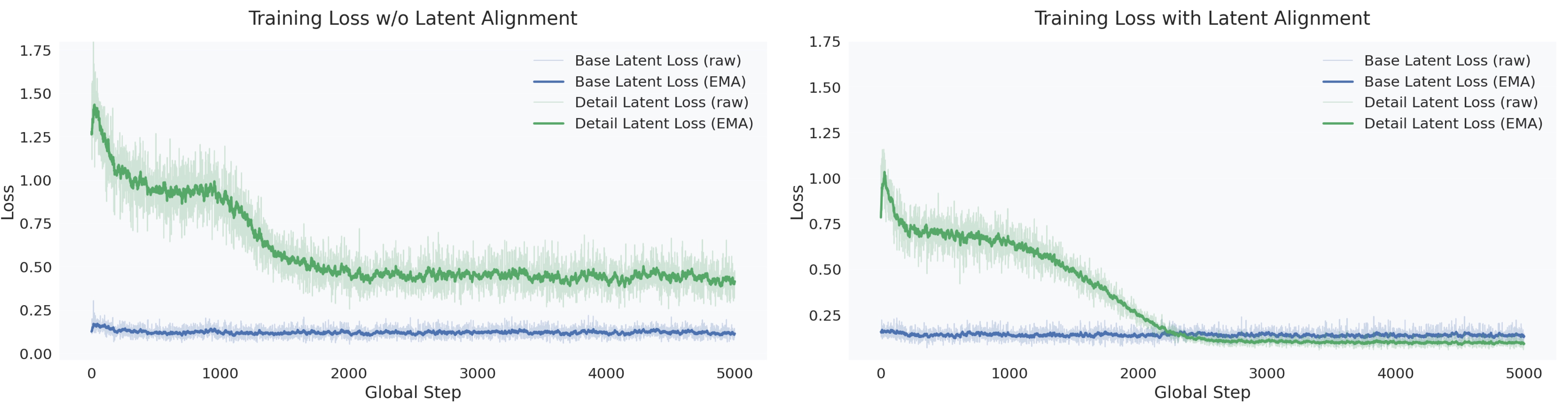
Reading guide: this figure plots the unweighted diffusion loss (per-token MSE) on the
base latent (blue) and the detail latent (green), showing raw curves (faint) and an EMA (solid). Without
latent alignment, the detail-latent loss decreases slowly and stays substantially higher than the
base-latent loss. With alignment, optimization becomes more stable and converges to a lower-loss solution;
the detail-latent loss eventually falls below the base-latent loss, indicating that the DiT learns a
well-structured distribution over the added detail channels.
Warm-start matters: zero-init and scheduling
Takeaway: Preserving pretrained behavior at initialization makes fine-tuning stable and efficient.
Evidence: Removing zero-init increases FID-10k to 29.73, and removing the scheduler degrades FID-10k from 9.27 to 9.80 (see Component Ablations). Zero-init also yields faster convergence in the zero-init comparison.
Interpretation: The extra heads start as no-ops, then the model gradually learns the new detail distribution.
Component Ablations (FID-10k)
| Method |
Alignment |
Zero Init |
Weight Scheduler |
FID-10k |
| Ours (full) |
yes |
yes |
yes |
9.27 |
| w/o alignment |
no |
yes |
yes |
16.37 |
| w/o zero init |
yes |
no |
yes |
29.73 |
| w/o weight scheduler |
yes |
yes |
no |
9.80 |