Landmark-aware Self-supervised Eye Semantic Segmentation
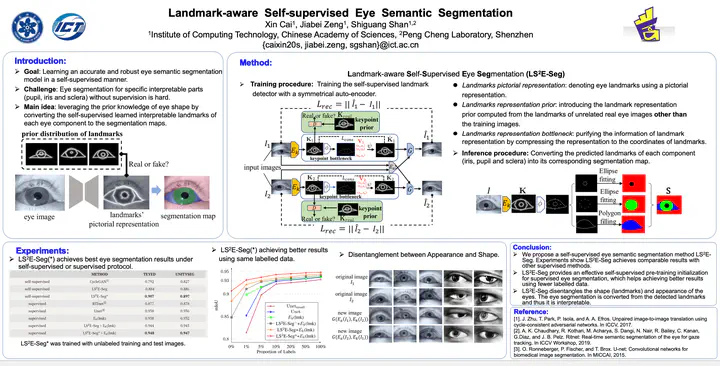 Overview
Overview
Abstract
Learning an accurate and robust eye semantic segmentation model generally requires enormous training data with delicate segmentation annotations.However, labeling the data is time-consuming and manpower-consuming. To address this issue, we propose to segment the eyes using unlabelled eye images and a weak empirical prior on the eye shape. To make the segmentation interpretable, we leverage the prior knowledge of eye shape by converting the self-supervised learned landmarks of each eye component to the segmentation maps.Specifically, we design a symmetrical auto-encoder architecture to learn disentangled representations of eye appearance and eye shape in a self-supervised manner. The eye shape is represented as the landmarks on the eyes.The proposed method encodes the eye images into the eye shapes and appearance features and then it reconstructs the image according to the eye shape and the appearance feature of another image.Since the landmarks of the training images are unknown, we require the generated landmarks’ pictorial representations to have the same distribution as a known prior by minimizing an adversarial loss.Experiments on TEyeD and UnitySeg datasets demonstrate that the proposed self-supervised method is comparable with supervised ones. When the labeled data is insufficient, the proposed self-supervised method provides a better pre-trained model than other initialization methods.